

3·
6 months agoIt happens to the best of us 🙂

It happens to the best of us 🙂
Also, could you please update the title of your fediverse post? The article now says 21k 🙂
If you need to provide tools that cross security boundaries then […] a small web app is better [than sudo].
A web app? Effin really!!? 🤨

Usually people use Hugo.
But I would be very interested in a less contrived alternative.
Thanks for doing this.

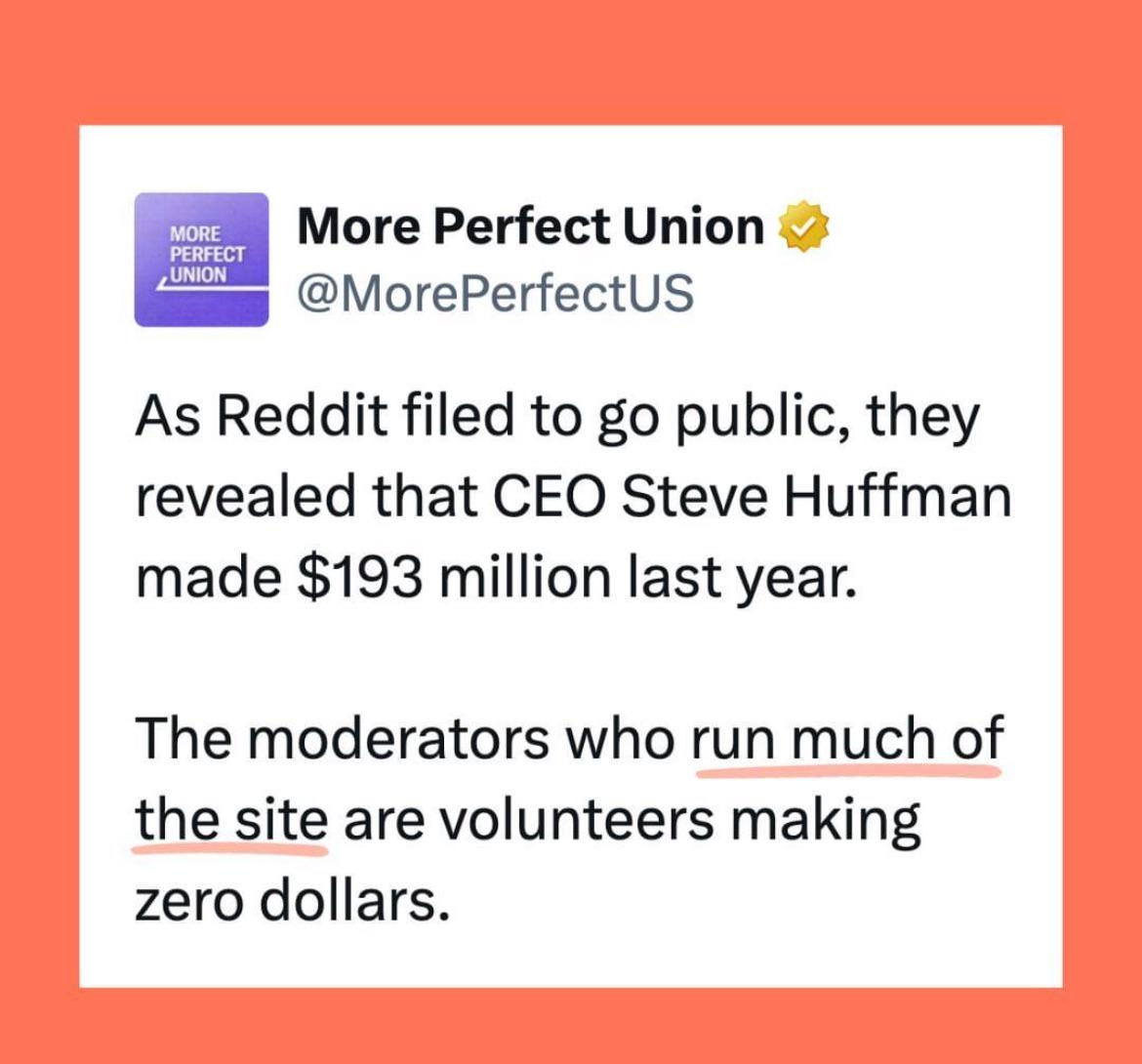
It turns out that “Women Who Code Closing - Women Who Code” actually isn’t about Women that code a software called “Closing”, and Women that code in general.
In fact, what they meant to write was:
The End of an Era: “Women Who Code” Closing – Women Who Code.
I know I’m gonna get downvoted for this, but punctuation matters, and sadly, it has to be said. So here I go.
Maybe they mean it in the sense of “forgery”. You know, as in “let people imagine what it is like to have friendships, by letting them make forgeries of their lives, but with friends in it” 🤪
Fuck yea!
I think we can all agree on that… But without the entire article, one can only parametrise their answer… I was hoping someone with a full version could do an HTML dump. 😅
Or at the very least a markdown dump in here.
Is it using XLR?
Is it just me, or is everyone here commenting on a half article, the other half being behind a paywall? 😬

But use the widows version and the proton layer. The Linux version is horribly coded.
I think you’re overstating the compute power […]
I don’t actually think so. A100 GPUs in server chassis have a 400 or 500W TDP depending on the configuration, and even if I’m assuming 400, with 4 per watercooled 1U chassis, a 47U rack with those would consume about 100kW with power supply efficiency and whatnot.
Running those for a day only would be 2.4GWh.
Now, I’m not assuming Amazon would own 100s of those racks at every DC, but they probably would use at least a couple of such racks to train their model (time is money, right?). And training them for a week with just two of those would be 35GWh, and I can only extrapolate from there.
So I don’t think that going to TWh is such an overstatement.
[…] and understating the amount of cardboard Amazon uses
That, very possibly.
I have seldom used Amazon ever, maybe 5 times tops, and I can only remember two times. Those two times, I ordered a smartphone and a bunch of electronics supplies, and I don’t remember the packaging being excessive. But I know from plenty of memes that they regularly overdo it. That, coupled with the insane amount of shit people order online… And yes, I believe you are right on that one.
Even so, as long as it is cardboard, or paper, and not plastic and glue, it isn’t a big ecological issue.
However, that makes no difference to Amazon financially, cost is cost, and they only care about that.
But let’s not pretend they are doing a good thing then. It is a cost effective measure for them, that ends up worsening the situation for everyone else, because the tradeoff is good economically, and terrible ecologically.
If they wanted to do a good thing, they could use machine learning to optimise the combining of deliveries in the same area, to save on petrol, and by extension, pollution from their vehicles, but that would actually worsen the customer experience, and end up costing them more than it would save them, so that’s never gonna happen.
IMHO the issue is two folds:
Yeah, it is one of the least bad uses for it.
But then again, using literal tera-watts-hours of compute power to save on the easiest actually recyclable material known to man (cardboard), maybe that’s just me, maybe I’m too jaded, but it sounds like a pretty bad overall outcome.
It isn’t a bad deal for Amazon, tho, who is likely to save on costs, that way, since energy is still orders of magnitude cheaper than it should be[1], and cardboard is getting pricier.
if we were to account for the available supply, the demand, and the future (think sooner than later) need for transition towards new energy sources… Some that simply do not have the same potential. ↩︎
The thing is, devops is pretty complex and pretty diverse. You’ve got at least 6 different solutions among the popular ones.
Last time I checked only the list of available provisioning software, I counted 22.
Sure, some like cdist are pretty niche, but still, when you apply for a company, even tho it is going to either be AWS (mostly), azure, GCE, oracle, or some run of the mill VPS provider with extended cloud features (simili S3 based on minio, “cloud LAN”, etc), and you are likely going to use terraform for host provisioning, the most relevant information to check is which software they use. Packer? Or dynamic provisioning like Chef? Puppet? Ansible? Salt? Or one of the “lesser ones”?
And thing is, even among successive versions, among compatible stacks, the DSL evolved, and the way things are supposed to be done changed. For example, before hiera, puppet was an entirely different beast.
And that’s not even throwing docker or (or rkt, appc) in the mix. Then you have k8s, podman, helm, etc.
The entire ecosystem has considerable overlap too.
So, on one hand, you have pretty clean and useable code snippets on stackoverflow, github gist, etc. So much so that tools like that emerged… And then, the very second LLMs were able to produce any moderately usable output, they were trained on that data.
And on the other hand, you have devops. An ecosystem with no clear boundaries, no clear organisation, not much maturity yet (in spite of the industry being more than a decade old), and so organic that keeping up with developments is a full time job on its own. There’s no chance in hell LLMs can be properly trained on that dataset before it cools down. Not a chance. Never gonna happen.
Do bullets kill soldiers?
Infantry soldiers in the open, possibly. Soldiers in an APC? No.
Same applies to companies. A single sufficient bad review on a small, one-person company can take it out entirely. A single review of a big corporation? Not even one from a big shot like MKBHD.
This headline is dumb.
I believe you’re missing the actual causality chain here.
While it is actually proven that vendors will degrade your experience artificially to “motivate” you to buy new devices, in the never ending pursuit of monetary gain, there is no such potential incentive here: you aren’t paying for new drivers.
And while others suggest biases, I do believe you are witnessing an effect that is at least partially real, if not totally, but not for the reasons you believe:
Most programs that leverage GPUs end up being GPU bottlenecked. Meaning that one can almost always improve the program’s performance by using a better GPU.
But then, why does a new driver not improve performance, and rather, simply “bring a degraded performance back to previous levels”?
Well, that has to do with auto-updates, and the way drivers are distributed.
While, in a world where one would have to manually update everything, a new driver would almost certainly mean better performance for a given program, most programs in our world auto-update automatically (and sometimes even, silently). And the developers are usually on top of things wrt drivers, because they follow drivers updates closely, get early versions, etc.
Meaning that when a driver is updated, your apps usually are, too. In a way that leverage the new driver for more processing, rather than faster processing. But unlike your automatically updated apps, your drivers are updated manually.
And the consequence of such updates, when you are too slow to update your drivers, is a degraded experience.
Not because anyone artificially throttled your device’s performance, but because you lag too much behind expected updates.
And Docker initially used Ubuntu. They explicitly and specifically switched to Alpine in 2016 for performance, to minimise the overhead.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Hi! Great post, good research with sources, great initiative, thank you. 🙏